

José Portolés
Jefe de Nefrología del Hospital Puerta de Hierro. Miembro del grupo BIGSEN de la Sociedad Española de Nefrología
En nefrología tenemos muchas enfermedades que entran en esta categoría, desde las propiamente hereditarias, como determinadas tubulopatías, la enfermedad de Fabry o las magnesemias hereditarias, hasta otras patologías en las que lo que se hereda es una predisposición genética y se necesita un desencadenante para activar la enfermedad, como ocurre en las glomerulopatías o el síndrome hemolítico urémico.
La Sociedad Española de Nefrología (SEN) cuenta con varios grupos de trabajo que interactúan en este ámbito. Tenemos BIGSEN, el grupo al que yo pertenezco, que es un grupo transversal que intenta apoyar a los demás en el desarrollo del análisis masivo de datos. Contamos también con el grupo de enfermedades hereditarias, que trabaja en asociación con instituciones europeas, y con la parte clínica, que es GLOSEN. En este grupo se incluyen todas estas enfermedades que, por estadística, son minoritarias y presentan un componente genético predisponente, como las glomerulonefritis. Disponemos asimismo de registros de enfermedades renales minoritarias, como el síndrome de Alport o el de poliquistosis hepatorenal. La SEN, en general, aporta un importante trabajo cooperativo basado en la integración y el análisis de datos.
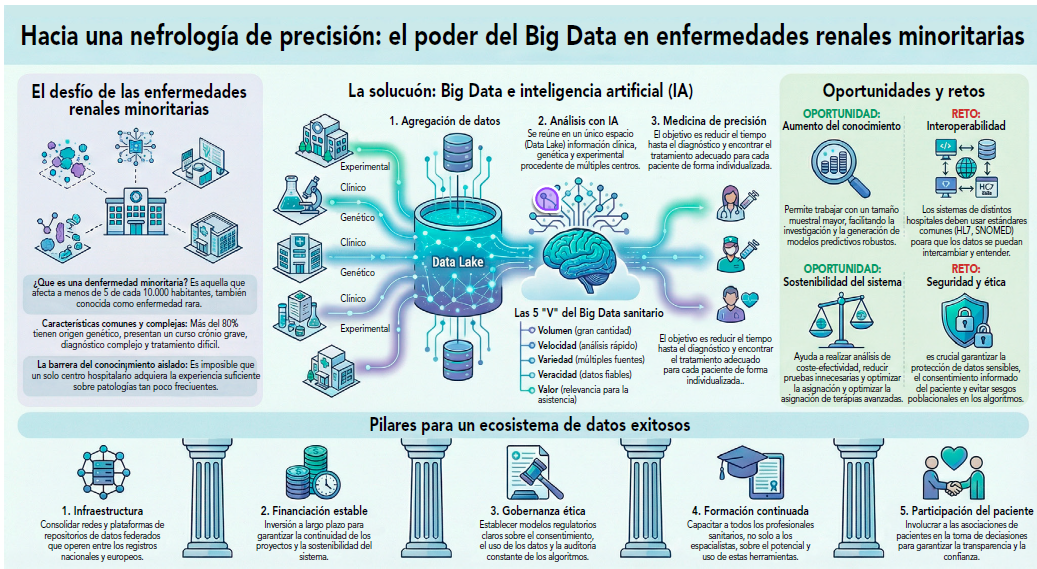
Lo que permite el Big Data es reunir en un único espacio la información procedente de muchos centros. Es imposible que un solo centro adquiera el conocimiento, la investigación y el desarrollo suficientes sobre enfermedades tan poco frecuentes. Al reunir todos estos datos en grandes data lakes, se facilita una integración que, junto con la inteligencia artificial, permite detectar patrones ocultos, predecir respuestas o identificar posibles tratamientos. En suma, se trata de reducir el tiempo necesario para llegar al diagnóstico y al tratamiento adecuados para cada paciente.
En cuanto a los desafíos, a lo largo de la entrevista hablaremos de la dificultad de la interoperabilidad de estos sistemas. Otro gran desafío es la protección de los datos sensibles.
Me gustaría mencionar algunas iniciativas que ya están funcionando, especialmente para quienes nos escuchan y puedan ser pacientes con enfermedades minoritarias o familiares. Hay proyectos encabezados por el Centro de Regulación Genómica de Barcelona, que trabaja con la Harvard Medical School, orientados a interpretar mutaciones responsables de enfermedades raras, como el proyecto popEVE. Este proyecto ha reunido datos de 31.000 familias de pacientes con enfermedades graves y ha sido capaz de identificar 123 nuevos genes patogénicos.
También existe un proyecto muy interesante del Centro de Supercomputación de Barcelona, orientado a integrar datos genéticos, clínicos y experimentales. Y, a nivel europeo, está el proyecto ERDERA, dotado con 380 millones de financiación para los próximos diez años. Su objetivo es desarrollar inteligencia artificial basada en macrodatos para aplicar medicina de precisión en terapias avanzadas. En él participan 37 países, incluido España, y varios centros de referencia nacionales.
Asimismo, contamos con el Espacio Europeo de Datos en Salud, que funciona bajo unas reglas de colaboración muy estrictas basadas en los principios FAIR data, que garantizan la interoperabilidad para la investigación. Y disponemos de dos redes europeas, ERKNet y ERKReg, que son registros europeos de enfermedades raras.
Todos estos data lakes, que se están creando a nivel de distintas comunidades autónomas españolas, luego a nivel del Ministerio y finalmente a nivel europeo, están trabajando para integrarse entre sí, crecer y compartir información. Esto, por supuesto, genera retos científicos, técnicos y éticos.
Hay que garantizar la seguridad de esos datos, asegurarse de que no salgan de la red que los custodia y dejar bien establecido quién es el propietario y quién el responsable de su custodia. Otro reto ético importante es evitar los sesgos poblacionales. En general, los lugares con menor desarrollo económico y sanitario estarán infrarrepresentados, y debemos trabajar, especialmente en el ámbito europeo, que es donde se desarrolla todo esto, para garantizar la equidad en el acceso. No puede ser que vivir en una u otra región de España determine tener más o menos acceso.
El tercer reto importante es la formación de los profesionales. No solo quienes trabajan directamente con estas herramientas y plataformas, sino todos los profesionales de la red sanitaria pública deben recibir periódicamente información sobre qué pueden esperar de estos sistemas interconectados. Interoperabilidad es una palabra que a todos se nos atraganta, pero significa simplemente intercambio de datos en un lenguaje que las máquinas puedan entender.
Cuando hablamos de Big Data, hablamos de las cinco “V”: la primera V es el volumen; la segunda, la velocidad de computación; la tercera, la variedad en la procedencia de los datos; la cuarta, la veracidad, es decir, que sean datos contrastados y fiables; y la quinta es el valor, porque deben ser datos relevantes. Hoy en día todos llevamos relojes inteligentes que recogen multitud de datos, cámaras, analizadores de laboratorio… miles de fuentes. Pero lo importante es que los datos aporten valor para mejorar la asistencia.
Si la pregunta es cómo garantizar la interoperabilidad de los sistemas. Esto se basa fundamentalmente en tres pilares: estándares comunes de comunicación, anonimización y cifrado de datos. El estándar más conocido desde hace años es HL7, que permite la comunicación entre distintos lenguajes y fuentes de datos para que se entiendan entre sí. Para texto libre, por ejemplo, tenemos el sistema de codificación SNOMED. Necesitamos estos estándares comunes de identificación; necesitamos anonimizar los datos para poder trabajar de forma segura; y necesitamos cifrarlos, manteniendo la posibilidad de reidentificarlos cuando sea imprescindible realizar una intervención. Todo ello debe estar sometido a estrictas auditorías de calidad para garantizar la seguridad de estos data lakes, que siempre deben operar bajo el marco regulatorio de redes públicas o consorcios público-privados que aseguren la protección del dato. Y deben depurarse periódicamente para garantizar su calidad.
Como siempre, me gusta poner ejemplos de lo que ya está en marcha. Tenemos un espacio nacional de datos interoperable con el espacio europeo, que funciona en fase piloto desde 2023 y aspira a disponer de la información clave de todos nosotros, usuarios de la sanidad pública, para dos fines: permitirnos ser atendidos en cualquier lugar de la Unión Europea con información básica compartida; y posibilitar la investigación y la detección de enfermedades poco frecuentes en el futuro. También existe un Registro Estatal de Enfermedades Minoritarias, gestionado por el Instituto de Salud Carlos III, y una red específica de patologías pediátricas llamada Red Únicas.
Por último, quiero mencionar la Red Europea de Enfermedades Raras, que utiliza la terminología inglesa y donde se habla de rare diseases. Es la ERKNet, una red que incluye a muchos países, y en la que España participa a través de los centros CSUR. Un CSUR es un centro público de referencia nacional que, por sus características, ha obtenido esta acreditación y debe ser el lugar de derivación para estas enfermedades poco frecuentes. Podemos mencionar, por ejemplo, el Hospital 12 de Octubre, el Hospital La Paz, el Clínic de Barcelona, Sant Joan de Déu o la Fundación Puigvert. Todos ellos cuentan con un CSUR, es decir, un centro de referencia unificado a nivel nacional.
En definitiva, hablamos de espacios de datos compartidos que presentan un reto técnico de gestión de grandes volúmenes de información, un reto ético y de seguridad que debe resolverse, y un reto de interoperabilidad, es decir, de comunicación entre sistemas, imprescindible para que todo este esfuerzo resulte realmente útil.
En economía de la salud debemos considerar tres elementos básicos: evaluación, eficiencia e investigación. En cuanto a evaluación, el Big Data nos permite construir modelos para estimar los costes reales y realizar análisis de coste-efectividad de estas nuevas terapias, especialmente las dirigidas a personas con enfermedades minoritarias. Podemos hacer modelos que simulen el impacto presupuestario de una nueva medida terapéutica a partir de datos reales. Cuando evaluamos un tratamiento, si queremos hacerlo bien, debemos analizar muchos elementos secundarios. No se trata solo de cuánto cuesta un nuevo fármaco o una nueva terapia y cuánto invertimos en ellos, sino de cuánto estamos ganando en años de vida, en calidad de vida, en ingresos hospitalarios evitados, en desplazamientos no realizados, en jornadas laborales recuperadas. Toda esta evaluación compleja requiere integrar datos de múltiples fuentes, y aquí el Big Data es fundamental.
Respecto a la eficiencia del sistema, si somos capaces de utilizar el Big Data para llegar antes a un diagnóstico de una enfermedad minoritaria mediante estos data lakes y herramientas de comparación, podremos reducir pruebas innecesarias o tratamientos costosos.
La tercera pata, donde el Big Data puede ayudar en farmacoeconomía, es la investigación. Hoy en día se puede realizar, junto con la investigación clínica convencional, una investigación basada en los datos ya disponibles. Si tengo cientos de miles de pacientes en un lago de datos, con información sobre qué les ha sucedido y qué tratamientos han recibido, puedo realizar investigación simulada: puedo buscar gemelos digitales, es decir, pacientes que se parezcan al caso clínico que estoy analizando, y observar su evolución. Por comparación, puedo identificar cuáles podrían ser los mejores tratamientos para un paciente concreto. Además, el Big Data y la inteligencia artificial nos ayudan a investigar en dos campos fundamentales: el diseño de nuevos compuestos y la simulación de proteínas y procesos genéticos. Podemos poner a las máquinas a trabajar para buscar secuencias químicas con potencial valor terapéutico.
En definitiva, se trata de utilizar toda esta información para lograr un sistema más coste-eficiente y, por tanto, más sostenible. Es importante entender que lo que buscamos no es ahorrar dinero, sino garantizar la sostenibilidad del sistema, basándonos en el análisis que permite el Big Data. El reto ético aquí es evitar que los algoritmos acaben priorizando criterios exclusivamente económicos y comprometan el acceso equitativo a terapias innovadoras. Por ello, siempre que estos análisis estén tutelados por instituciones científicas, como sociedades médicas o los sistemas nacionales de salud, tendremos una garantía sólida de que las cosas van por el buen camino.
JP: Nos pueden ayudar mucho. Hablemos de forma conceptual. ¿Qué estamos haciendo con la inteligencia artificial y con el Big Data? Estamos introduciendo una cantidad enorme de información sobre cosas que ya han ocurrido: datos de muchos países, de muchos escenarios y de múltiples situaciones clínicas. Cuando tengo un paciente con una enfermedad muy poco frecuente, mi problema como médico en la práctica diaria es que no dispongo de suficiente experiencia para comparar ese caso con otros similares. Sin embargo, gracias a esos data lakes que ya hemos mencionado, respaldados por sistemas sanitarios públicos y por regulaciones europeas, y potenciados por una capacidad de análisis extraordinaria, puedo tomar a mi paciente y compararlo con otros pacientes similares. En mi experiencia cotidiana, en los últimos cinco años quizá no haya visto suficientes casos que se parezcan; pero en una fuente que acumula información de muchos países y miles de pacientes, sí voy a encontrar un número mucho mayor de casos comparables. Esto nos permite prever cómo puede evolucionar nuestro paciente en función de cómo han evolucionado pacientes parecidos. El objetivo es anticiparnos a la progresión de la enfermedad y evitar complicaciones.
Aunque no es exactamente una enfermedad minoritaria, me gustaría comentar dos ejemplos. El primero procede del ámbito del trasplante renal. Existe una herramienta de inteligencia artificial ya registrada como herramienta terapéutica, aunque no sea un fármaco, llamada iBox. iBox es una herramienta desarrollada durante muchos años en Francia, que integra datos genéticos, datos de biopsias, datos clínicos y datos de evolución del paciente. Cuando tengo un paciente problema, lo enfrento a esa “caja” de inteligencia artificial y el sistema busca, por comparación, a qué situaciones previas se parece. Me ayuda a identificar qué le está ocurriendo realmente al paciente y cuál es el mejor manejo posible. Pensemos que en trasplante renal el reto es lograr una inmunosupresión equilibrada: suficiente para evitar el rechazo, pero sin excedernos, porque ello incrementaría el riesgo de infecciones o tumores. Ese equilibrio delicado, anticipar un rechazo o identificar sus fases iniciales sin recurrir a una dosis excesiva de inmunosupresión, es precisamente lo que permite afinar iBox. En España ya se está trabajando con biopsias de protocolo programadas, datos genéticos, datos del donante y del receptor, y el historial clínico completo del paciente. Toda esa información se integra en el sistema, que, a partir de decenas de miles de casos comparables, predice con un grado de acierto notable qué es lo que puede suceder.
El segundo ejemplo procede del propio grupo BIGSEN, donde se están desarrollando algoritmos para identificar qué pacientes con enfermedad renal crónica van a progresar más con rapidez, especialmente en aquellos que disponen de datos genéticos.
En definitiva, la inteligencia artificial, gracias a su enorme volumen de información y a su capacidad de análisis, nos permite predecir qué puede ocurrirle a un paciente en función de lo que ya les ha ocurrido a muchos otros pacientes muy similares.
La construcción de ecosistemas de datos requiere la implicación de clínicos, economistas, informáticos y gestores. ¿Cómo se está abordando esta colaboración en el ámbito nefrológico y qué papel deberían jugar las sociedades científicas?
JP: Esto solo se concibe como un esfuerzo multidisciplinar. No se trata de un nefrólogo con curiosidad por la genética o de un genetista al que le gusta la informática y programa: se trata de equipos multidisciplinares con clínicos, genetistas, investigadores e ingenieros de datos. Desde hace algunos años existen titulaciones específicas en bioinformática, profesionales cuyo objetivo es precisamente unir estas dos disciplinas, la informática y el análisis de datos, con conocimientos básicos de biología y clínica. Por tanto, este trabajo solo puede entenderse como un esfuerzo multidisciplinar.
El papel de las sociedades científicas es fundamental. Son garantes e integradoras del trabajo. Existen convocatorias específicas de investigación y financiación de instituciones como el Instituto de Salud Carlos III, que lidera la investigación sanitaria pública en este país. Hay convocatorias especializadas en medicina personalizada y en transformación digital, y las propias sociedades científicas también cuentan con fuentes de financiación, aunque más modestas. Pero su papel como garantes e integradoras del trabajo es clave.
Aquí me gustaría ampliar un poco el foco más allá de las enfermedades minoritarias hacia algo que afecta a toda la población. Hay dos grandes retos hoy en día. Uno es estudiar las enfermedades minoritarias poco conocidas siguiendo un enfoque “de abajo arriba”: llega un caso de un paciente con una enfermedad que no se parece a nada, que tiene un componente genético y que debemos investigar para identificar qué hay detrás y cómo tratarlo. Todo lo que estamos comentando sobre Big Data nos ayuda a buscar casos similares.
Pero hay un abordaje global aún más relevante. No sé si sabe que, entre los pacientes que inician hemodiálisis en este país cada año, aproximadamente un 20 % tiene una enfermedad renal crónica no filiada. ¿Por qué? Porque llegan al diagnóstico en fases finales, cuando ya no es posible identificar qué ha dañado sus riñones. En ese 20 % de pacientes, se estima que hasta un 30 % tiene un componente genético. Uno de los grandes retos que se han marcado las sociedades científicas hoy es utilizar el Big Data y la inteligencia artificial para reducir esa incertidumbre. Se trata de identificar a estos pacientes que han llegado a diálisis sin diagnóstico, muchas veces porque su enfermedad ha sido silente, con pocas manifestaciones clínicas, para tratarlos de forma más adecuada.
La Sociedad Europea de Nefrología ha publicado recientemente una iniciativa cuyo objetivo es reducir el número de pacientes con enfermedad renal crónica no filiada. Lo que están haciendo es crear un espacio compartido de datos con un informe estándar en el que se registra toda la información renal disponible en el momento en que un paciente accede al nefrólogo: la biopsia, si existe, aunque a veces no aporta información porque llega tarde y solo muestra cambios avanzados; el estudio genético, si se ha realizado; y todos los datos de laboratorio asociados. Este caso se incorpora a un conjunto de casos no definidos, que se revisan periódicamente para evaluar si los nuevos avances permiten asignar un diagnóstico más preciso.
Algunos pacientes con enfermedades minoritarias, como el síndrome hemolítico urémico, pueden haber pasado desapercibidos o haber sido mal clasificados como otra patología que terminó destruyendo el riñón y llevando al paciente a diálisis. Si no sabemos que ese paciente padece un síndrome hemolítico urémico, estará en grave riesgo de perder un trasplante renal. No voy a poder recuperar su riñón, pero sí podré trasplantarlo con mayor seguridad si lo identifico correctamente.
En otras patologías, como la enfermedad de Fabry, las alteraciones enzimáticas comienzan en fases muy precoces, incluso en la infancia, y pueden pasar inadvertidas, provocando después una progresión renal y cardiovascular acelerada. El paciente llega a diálisis sin diagnóstico. No podremos sacarlo de diálisis, pero sí podremos proteger su corazón y evitar que fallezca por un problema cardiovascular.
En España están trabajando en esta línea el grupo BIGSEN, el grupo de enfermedades hereditarias y el grupo europeo. Y quiero destacar que, actualmente, la Sociedad Europea de Enfermedad Renal (ERA, por sus siglas en inglés, European Renal Association) está presidida por una española, la doctora Roser, experta en enfermedades hereditarias. Es la primera mujer en ocupar el cargo, y lo más relevante: es una especialista española que lideró el grupo de nefropatías hereditarias de la SEN. Por tanto, creo que vienen buenos tiempos para avanzar simultáneamente en dos líneas: reducir la incertidumbre diagnóstica en los pacientes renales no filiados y desarrollar el conocimiento y la colaboración en las enfermedades minoritarias. Estoy seguro de que ella, como presidenta, impulsará durante su mandato estas líneas de investigación.
Finalmente, ¿qué pasos considera esenciales para consolidar el uso de Big Data en la investigación y evaluación económica de las enfermedades renales raras en España, garantizando su sostenibilidad a largo plazo?
JP: Lo primero es la infraestructura. Hay que consolidar redes, y esto ya está avanzando y es una realidad hoy en día. Es necesario fortalecer redes de investigación como la que hemos mencionado en pediatría, la Red Únicas, o conectar los registros nacionales con los registros europeos para crear plataformas de repositorios federados que operen entre sí.
En segundo lugar, la financiación. Hay que invertir dinero, y hay que hacerlo con visión, con proyección a muchos años, sabiendo que la inversión que realizamos ahora la recuperaremos en forma de reducción de enfermedad, mejora de calidad de vida, incremento de supervivencia y, en última instancia, en un sistema más coste-eficiente y sostenible. La financiación tiene múltiples vías, pero es esencial que la sanidad pública disponga de modelos de continuidad que garanticen la sostenibilidad en el tiempo.
El tercer paso es la gobernanza ética. Hay que regular todo este proceso. Pensemos que estamos hablando de integrar y analizar todos los datos en conjunto, algo que puede generar recelos sobre la pérdida de libertad o el uso indebido de la información. Lo que hay que hacer no es dejar de compartir datos, sino compartirlos bajo una regulación adecuada y con una gobernanza ética sólida: marcos claros sobre el consentimiento del paciente, la posibilidad de retirar ese consentimiento, límites para el uso secundario de los datos y revisión constante de los algoritmos que los manejan. En este punto, Europa es mucho más reguladora que Estados Unidos o China. Esto nos hace avanzar más despacio, pero también de forma más segura. En las manos equivocadas, los datos de salud pueden ser peligrosos para la población. Imagine que la empresa a la que pido una hipoteca o un seguro conoce que tengo una alteración genética que acortará mi vida: podría elevarme los intereses o directamente negarme el seguro. Por eso son necesarios infraestructura sólida, financiación estable, gobernanza ética y liderazgo intelectual de los mejores. Ahí es donde entran los centros de referencia en España, los CSUR, y, a nivel europeo, las redes de referencia.
Todo esto describe cómo funciona la maquinaria. Hay que considerar además a quienes van a utilizarla: los profesionales. Cualquier médico, no solo quienes trabajan en centros altamente tecnológicos, necesita formación continua y herramientas sencillas que le permitan saber cómo actuar con un paciente complejo. Lo comentábamos antes: las enfermedades minoritarias contactan muchas veces con atención primaria o con especialistas en hospitales no de referencia. Es difícil que un profesional pueda resolver solo situaciones tan complejas. Debe saber a qué recursos recurrir, qué centros CSUR pueden atender al paciente, cuándo pedir una segunda opinión y qué opciones puede ofrecer.
Y el último elemento, fundamental, es la participación del paciente. Todo esto se hace por el paciente; todos acabaremos siendo pacientes en algún momento. Yo mismo ya he estado al otro lado. La participación del paciente da sentido a toda esta estrategia y es imprescindible incorporar a las asociaciones de pacientes de enfermedades minoritarias o renales, muy potentes en España, a la toma de decisiones y a la revisión de la gobernanza, para garantizar transparencia y confianza.
En resumen, los pilares esenciales son: infraestructura, financiación estable, gobernanza ética, formación continuada para todos los sanitarios y participación del paciente.
Sin estos pilares, la innovación tecnológica no se traducirá en mejoras reales para los pacientes.
Es un tema apasionante, con muchas facetas. Podríamos hablar horas de esto. Pero debemos tener claro mi mensaje final: el ser humano se enfrenta a una nueva revolución tecnológica, que es el Big Data y la inteligencia artificial. Tenemos que tomar las riendas para mejorar nuestro sistema sanitario y dar más oportunidades a nuestros pacientes. No hay marcha atrás: no podemos caer en el “terraplanismo” tecnológico. Debemos guiar esta evolución para que sea provechosa, ética y segura.








")





{kind=link}